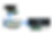165 results found with an empty search
- RocketStor 6430TS Series: Online Array Roaming (AKA RAID Roaming)
RocketStor 6430TS Series (RS6430TS) 12Gb/s SAS / 6Gb/s SAS/SATA RAID enclosures support Online Array Roaming. This feature is also known as “RAID Roaming”, and allows customers to migrate drives from one RS6430TS enclosure to another, without having to start from scratch or recover an array. You can even do this while the host system remains “Online” (powered on and operational). In the above screenshot, 4 hard drives (shown on the right) are configured as a RAID 0 array, and were originally hosted by a RocketStor 6434TS enclosure. Thanks to the Array Roaming feature, these drives can be moved directly to a RocketStor 6438TS (shown on the left). The drives can be installed randomly – the original disk order does not need to be preserved; the enclosure’s RAID controller will sort this out for you. Customers are not restricted to a RS6430TS-to-RS6430TS transition. The RAID array would be recognized by any RocketRAID 3700 (RR3700) series controller, or even an older RockerStor 6400TS/AS series RAID enclosure (which utilize RR2700 and RR4500 series 6Gb/s SAS/SATA RAID controllers). How to Use Array Roaming while the system is online Hot-Plug and Hot-Swap capability make this possible. An administrator can use the WebGUI or CLI management utilities to power-down and “park” the drives, which can then be moved from one controller/enclosure to another. For this example, we will be using the WebGUI. 1.The Unplug command is provided under the WebGUI’s Logical tab. 2.Click the Maintenance link on the far-right of the interface; this will open a sub-menu. 3.The sub-menu will display several options. Click “unplug” – this will safely power off each disk, and allow them to spin-down (this process is sometimes referred to as “parking”. Once the controller/enclosure determines the drives or ready, it will display a message on screen – the drives can now be physically removed. Once the drives have been moved to the second controller/enclosure, power on the unit, and give it a few seconds to allow the drives to spin up. 4.Click the Rescan button on the left side of the interface – the screen should refresh after a few seconds and display the array.
- Solving the AI Data Stalling Problem: Why Your Inference Cluster Needs a CDI Storage Tier
In the race to deploy Large Language Models (LLMs) and Generative AI, most organizations focus on the GPU. But as clusters scale, a hidden bottleneck emerges: Data Stalling. If your GPUs are waiting for data to arrive from a slow, monolithic storage array, you are paying for compute cycles you aren't using. The HighPoint RocketStor 4243AS is a new CDI (Composable Disaggregated Infrastructure) Hardware Storage platform designed to eliminate this bottleneck by turning high-performance NVMe media into a "liquid" resource for AI inference. The Bottleneck: Why Standard Storage Fails AI AI inference, particularly with LLMs, relies on a massive amount of "Context" data. This is often stored in a KV Cache (Key-Value Cache). · The Problem: In traditional "Scale-Up" storage, the controller becomes a chokepoint. When hundreds of inference requests hit the storage at once, latency spikes, and GPU utilization drops. · The Result: Slower "Time to First Token" (TTFT) and a degraded user experience for AI applications. The Solution: Disaggregated "Liquid" Storage The RocketStor 4243AS utilizes NVMe-oF (NVMe over Fabrics) to decouple storage from the GPU node. By moving storage to a dedicated CDI (Composable Disaggregated Infrastructure) tier, you gain three critical advantages for AI: 1. Zero-Copy Performance with RDMA Powered by the WDC RapidFlex™ C2000 controller, the RS4243AS supports RoCE v2 (RDMA over Converged Ethernet). This allows the GPU to pull data directly from the RS4243AS memory space, bypassing the CPU kernel. This "Zero-Copy" path reduces latency to near-local levels, ensuring your inference engines are never starved for data. 2. Massive Concurrency for KV Caching Unlike traditional arrays that struggle with thousands of simultaneous small-block requests, the RocketStor 4243AS is built for high-concurrency workloads. Its single-silicon, hardware-offload architecture maintains 200Gbps line-rate performance even under the heavy, random-read patterns typical of AI inference and vector database queries. 3. Power-Efficient Scale-Out AI data centers are already pushed to the limit of their power envelopes. HighPoint’s precision-engineered x1-lane-per-drive architecture is designed for maximum efficiency. It perfectly balances the internal PCIe bandwidth of 24 NVMe SSDs with the external 200GbE network fabric, reducing heat and power consumption compared to over-provisioned "Scale-Up" systems. The "Scale-Out" Advantage for AI Startups and MSPs For AI service providers, the RocketStor 4243AS offers a superior ROI model. Instead of buying a multi-million-dollar monolithic SAN upfront, you can deploy a single 24-bay RocketStor 4243AS node today. · Modular Growth: As your inference traffic grows, simply add another RocketStor 4243AS node. · BYOD Flexibility: Use any industry-standard U.2/U.3 NVMe SSDs to tailor your capacity and performance to your specific AI model’s needs. Conclusion: The New Foundation for AI In 2026, the winner of the AI race won't just be the one with the most GPUs—it will be the one with the most efficient data fabric. The HighPoint RocketStor 4243AS provides the "Liquid Infrastructure" needed to keep your AI models running at the speed of thought. Learn More HighPoint CDI Hardware Storage Platforms RocketStor 4243AS 24-Bay CDI Hardware NVMe Storage Platform Blog: The Death of "Stranded Capacity" — Why Your NVMe Storage is Only 60% Efficient Blog: Choosing Your Path — NVMe/TCP vs. RoCE v2 for the Modern Fabric
- Breaking the Local Storage Myth: Why RoCE and the RocketStor 4243AS are the New Standard for Disaggregated Storage
In the high-stakes worlds of AI development, 8K video post-production, and edge computing, there has long been a sacred rule: If you want maximum performance, the drives must be installed directly inside the target server. For years, this meant building "fat nodes"—servers stuffed with local NVMe drives. But this model creates a rigid architecture where you can't scale storage without buying more expensive CPUs, and you can't share fast storage across your cluster. Enter NVMe-oF (NVMe over Fabrics) and specifically RoCE (RDMA over Converged Ethernet). When paired with a high-density target like the RocketStor 4243AS, the "local performance" myth is officially busted. The Engine: What is RoCE? RoCE is an acronym for RDMA over Converged Ethernet, a networking protocol. To understand its value, you have to understand the CPU “tax" of traditional networking architecture. In standard TCP/IP networking, every time data moves from the network to a drive, the server’s CPU has to stop what it’s doing, process the packet headers, and manually copy data between memory layers. This creates latency and CPU overhead. RDMA (Remote Direct Memory Access) changes the game by allowing the network interface card (NIC) to move data directly from the memory of the storage target (the RocketStor 4243AS in this discussion) to the memory of the compute node (your Proxmox or AI server). · Zero-Copy: Data moves directly to its destination without being copied into intermediate buffers. · Kernel Bypass: The operating system's "middleman" is removed, allowing the hardware to talk directly to hardware. · Near-Local Latency: While a local NVMe drive might have a latency of ~10-30μs, a RoCE-tuned network adds only a negligible 2-5μs of overhead. The Vehicle: RocketStor 4243AS and Disaggregated Storage The RocketStor 4243AS is a specialized NVMe storage target designed to act as the "Shared Flash Bank" for your entire network. Built on a PCIe Gen4 x16 switch architecture, it manages up to 24 NVMe devices with non-blocking internal bandwidth. Each NVMe bay is allocated x1 dedicated PCIe Gen4 lanes for maximum efficiency and throughput over 100Gbe networking infrastructure. Why "Disaggregated" is Better: 1. Independent Scaling: Need more storage for your 8K RAW footage? Add another RocketStor 4243AS. Need more render power? Add a compute node. You no longer have to buy them together in a "fixed" server box. 2. Resource Pooling: Instead of having 20TB of "trapped" fast storage in one server, the RS4243AS creates a global pool. You can carve out Namespaces and assign them to any node on your 100GbE fabric. 3. High-Density Performance: Tailored for 2x 100GbE network bandwidth, the RocketStor 4243AS provides an ideal connectivity pipeline between the servers and NVMe storage. The x1 dedicated lanes per-bay bandwidth enables solution to efficiently saturate the network, ensuring your remote workers or AI nodes feel like they are working with local drives. Industry Impact: Real-World Gains Media & Entertainment (M&E) Working with 8K RAW video requires sustained throughput that traditional NAS simply cannot provide. By using the RocketStor 4243AS over a RoCE fabric, multiple editors can access the same high-speed NVMe pool simultaneously. The result? Zero dropped frames and the ability to edit directly off the network without slow proxy files. AI & Machine Learning AI training is "data-hungry." If your GPUs are waiting for data from a slow mechanical array or a congested TCP network, you are wasting expensive compute cycles. RoCE ensures the RS4243AS can "feed the beast" at the speed of flash, keeping GPU utilization at 100%. Enterprise Virtualization (Proxmox) For Proxmox users, the RS4243AS enables Software High Availability (HA). Because the storage is external and connected via high-speed RoCE, if one compute node fails, another node can instantly pick up the storage namespace and restart the VM with zero data loss and near-zero downtime. Conclusion: The perfect solution for 100GbE Networking The RocketStor 4243AS distributes x1 lanes for each of the 24 drive bays;ideal for 100GbE networking. It is specifically engineered to balance massive NVMe density with the most common high-speed fabric in modern servers. By leveraging RoCE, you aren't just moving storage outside the box—you are removing the boundaries of what your infrastructure can achieve. Disaggregated storage isn't just about saving space; it's about reclaiming the performance your hardware was built for. Learn More HighPoint CDI Hardware Storage Platforms RocketStor 4243AS 24-Bay CDI Hardware NVMe Storage Platform Blog: The Death of "Stranded Capacity" — Why Your NVMe Storage is Only 60% Efficient Blog: Choosing Your Path — NVMe/TCP vs. RoCE v2 for the Modern Fabric Bog: Solving the AI Data Stalling Problem: Why Your Inference Cluster Needs a CDI Storage Tier
- The "Blackwell" Audit: Scouring Massive SQL Databases with Portable Gen5 AI eGPU Enclosure
In the modern enterprise, data is the most valuable asset, but it is also the most cumbersome. For organizations managing massive SQL databases - ranging from financial ledgers to industrial logs - the challenge isn't just storing the data; it’s also the need to scour it for inconsistencies, errors, and hidden insights. With the arrival of NVIDIA’s Blackwell GPUs, the math of data intelligence has changed. However, these 1000W-class accelerators cannot be housed in standard laptops or aging office desktops. However, the emergence of portable Gen5 enclosures, such as the RocketStor 8631D (1300W) paired with the Rocket 7634D Gen5 Adapter, has effectively created a new category of productivity: The Portable AI Data Center. Here is how high-bandwidth, portable GPU acceleration is redefining productivity and efficiency in data-heavy industries. Eliminating the "Cloud Tax" and Privacy Friction For many sectors—such as healthcare, defense, and high-finance—uploading SQL databases to a cloud-based LLM is a non-starter due to regulatory compliance (HIPAA, SOC2) or the sheer volume of data involved. · The Gen5 Solution: By pairing a Compact Gen5 Workstation with the RocketStor 8631D, consultants can bring Blackwell-level compute directly to the data source · Productivity Boost: By bringing the RocketStor 8631D directly to the data source, analysts eliminate the days or weeks usually spent on security clearances and data sanitization for cloud transit. · Efficiency: Processing remains local. The LLM scours the database within the safety of the organization’s firewall, providing instant results without the latency or cost of multi-terabyte egress fees. From Sequential Queries to Parallel Intelligence Standard SQL queries are excellent at finding what you tell them to find. An LLM, however, can find what you forgot to look for. It can identify contextual "fat"—data entries that are technically valid but logically incorrect. · The Power of Parallelism: While a CPU handles logic, the GPU hosted by the RocketStor 8631D enclosure uses thousands of cores to analyze thousands of database rows simultaneously. · The Gen5 Pipeline: To feed a Blackwell GPU, you cannot rely on restrictive protocols like Thunderbolt. The Rocket 7634D host adapter provides a Native PCIe Gen5 x16 pipe (64GB/s). This ensures the GPU is never starved for data, allowing the LLM to ingest and scan massive SQL tables at the physical limit of the hardware. Why "Portable" Server-Class Hardware Matters You might ask: Why not just use a laptop? The reality is that Blackwell-class AI requires a Native PCIe Gen5 slot and massive power—two things a laptop cannot provide. The "Portable AI Factory" workflow utilizes a Small Form Factor (SFF) Gen5 Workstation and the RocketStor 8631D. This setup is small enough to fit in a protective travel case yet powerful enough to outperform a room full of standard servers. · Zero Infrastructure Burden: The client doesn't need to provide a supercomputer. A specialized consultant brings their own Blackwell-ready enclosure and Gen5 adapter, plugs into a local host, and begins the audit immediately. · 1300W Dedicated Power: The RocketStor 8631D’s integrated power supply ensures that a flagship Blackwell GPU has the consistent, high-amperage current it needs to hold complex audit models entirely in its 48GB+ VRAM. Application: Industrial Logistics & Inventory Normalization Large-scale manufacturing and global supply chains often suffer from "data decay"—duplicate part numbers, mismatched descriptions, and ghost inventory spread across regional SQL databases. · Productivity: An LLM-powered audit can reconcile "1/2-inch bolt" with "Bolt, .5in, Hex" across millions of entries in minutes. · Efficiency: A consultant can travel between regional warehouses with a portable GPU setup, cleaning local databases on-site to ensure global inventory accuracy without needing a massive server footprint at every location. Application: Financial Compliance and Forensic Auditing Forensic accountants often have to "scour" transaction logs for subtle patterns of fraud or non-compliance that don't fit a simple rule-based flag. · Productivity: Instead of a team of auditors manually reviewing flagged entries over a month, a high-performance GPU can run a local LLM to perform a "first pass" scan, highlighting high-probability anomalies for human review in a single afternoon. · Efficiency: The RocketStor 8631D’s integrated 1300W power supply allows for the use of flagship enterprise GPUs (like the RTX 6000 Ada Generation), which possess the massive VRAM (48GB+) required to hold complex audit models entirely in memory. Conclusion: The New Standard for Data Cleaning Scouring databases no longer has to be a manual, month-long process. By leveraging the mobility and raw 64GB/s bandwidth of the RocketStor 8631D and Rocket 7634D, organizations can transform cluttered SQL liabilities into streamlined assets. When you combine the cognitive power of an LLM with the portable muscle of an external Blackwell GPU, the "fat" in your data doesn't stand a chance. Learn More RocketStor 8631D PCIe Gen5 x16 External CopprLink Expansion Enclosure Rocket 7634D External PCIe Gen5 x16 CopprLink HIC Blog: Breaking the Server Chassis Barrier: The Rise of Composable GPU Infrastructure Blog: PCIe Disaggregation 101: Why the Server Chassis is Shrinking Blog: The 3 Pillars of HighPoint’s External CopprLink™ Architecture
- Blackwell Without the Burn: How to Move 1000W TDP Outside Your Chassis with Zero Performance Loss
The "Blackwell" Wall: When Air Cooling Isn't Enough The arrival of NVIDIA’s Blackwell generation of enterprise GPUs has pushed workstation design to a breaking point. With TDPs (Thermal Design Power) soaring toward 1000W, the traditional "internal" GPU setup is facing a physics problem: Heat Density. In a standard workstation, installing multiple Blackwell GPUs results in immediate thermal throttling. To keep the system from crashing, users have historically had to down-clock their hardware or settle for reduced lane speeds—essentially paying for a Ferrari but driving it in a school zone. Enter the RocketStor 8631C/D: The External Thermal Escape Pod The RocketStor 8631C/D is a dedicated eGPU solution designed specifically to rescue Blackwell and other high-TDP accelerators from the cramped, overheated confines of the workstation chassis. By moving the GPU into a dedicated external enclosure, you achieve three critical engineering goals: 1. Isolated Thermal Zones: The GPU's massive heat output is completely removed from the workstation’s CPU and memory. 2. Dedicated Power: With integrated 600W and 1300W power supply, the RocketStor 8631C and 8631D ensures the Blackwell GPus have the consistent, high-amperage current they need without overtaxing the workstation’s internal PSU. 3. High-Static Pressure Cooling: RocketStor 8631C and 8631D optimized enclosure design provides superior cooling airflow compared to dense, crowded desktop chassis. Zero Performance Sacrifice with CopprLink™ Historically, using external GPUs meant you had to settle for a performance compromise. Whether it was the protocol overhead of Thunderbolt™ or the signal degradation of passive cables, you inevitably lost speed. HighPoint’s External CopprLink PCIe Architecture changes the math. By using either the Rocket 7638D (Hybrid CopprLink/MCIO) or Rocket 7634D (CopprLink) adapter in tandem with the RocketStor 8631D, you create a Native Gen5 x16 Pipeline. · No Tunneling: Unlike USB4 or Thunderbolt, this is a direct PCIe connection. No "protocol tax." · Active Signal Management: Utilizing Astera Labs Retimers and Broadcom Switching technology, HighPoint manages the 32GT/s signals across the CopprLink cable. · Native 64GB/s: Your Blackwell GPU "thinks" it is plugged directly into the motherboard, delivering full 8K rendering and AI training speeds without the heat soak. Technical Spotlight: Choosing Your Engine Feature Rocket 7638D Rocket 7634D Primary Role The Hybrid Command Center The Dedicated Performance Link Architecture 48-Lane Gen5 Switching Gen5 x16 Direct Host Link Connectivity 1x External CDFP / 2x Internal MCIOx8 1x External CDFP Best For Users needing Internal NVMe + External GPU Pure point-to-point eGPU performance Learn More RocketStor 8631D PCIe Gen5 x16 External CopprLink Expansion Enclosure Rocket 7634D External PCIe Gen5 x16 CopprLink HIC Blog: Breaking the Server Chassis Barrier: The Rise of Composable GPU Infrastructure Blog: PCIe Disaggregation 101: Why the Server Chassis is Shrinking Blog: The 3 Pillars of HighPoint’s External CopprLink™ Architecture Blog: The "Blackwell" Audit: Scouring Massive SQL Databases with Portable Gen5 AI eGPU Enclosure
- Choosing Your Path — NVMe/TCP vs. RoCE v2 for the Modern Fabric
HighPoint’s RocketStor 4243AS CDI Hardware platform is a chameleon of the storage world. Because it is powered by the Western Digital RapidFlex™ C2000, it doesn’t force you into a single networking silo. You have a choice: the universal compatibility of NVMe/TCP or the extreme, low-latency power of NVMe/RoCE v2. But which one is right for your specific rack? 1. NVMe/TCP: The "Standard Ethernet" Powerhouse If you want to move to disaggregated storage without rewiring your entire data center, NVMe/TCP is your best friend. · How it works: It runs the NVMe protocol over standard, ubiquitous TCP/IP networks. · The Advantage: You don't need specialized "lossless" switches or complex network tuning. If you have a 100GbE switch and a standard NIC, you are good to go. · Best For: General-purpose virtualization (Proxmox/VMware), scale-out file systems, and mid-market enterprises looking for an easy SAN replacement. · The Trade-off: Since the host CPU handles the TCP stack, there is a small "CPU Tax" on your servers. 2. NVMe/RoCE v2: The "Zero-Copy" Speed Demon For those who need every microsecond of performance—think 8K uncompressed video editing or massive AI training sets—RoCE v2 (RDMA over Converged Ethernet) is the gold standard. · How it works: It uses Remote Direct Memory Access (RDMA) to move data directly from the RocketStor 4243AS into the Host Server’s RAM. · The Advantage: It bypasses the Host CPU entirely (Zero-Copy). This results in latency and throughput that effectively rivals a local PCIe Gen4 drive. · Best For: AI/ML model training, high-frequency trading, and real-time 8K media production. · The Trade-off: It requires "Lossless Ethernet" configuration (PFC/DCB) on your switches and a RoCE-capable SmartNIC for your servers. The RocketStor 4243AS Difference Whether you choose TCP for its flexibility or RoCE for its raw speed, the RocketStor 4243AS is is the solution of choice. Because the RapidFlex C2000 handles the heavy lifting of the protocol offload, the storage enclosure itself never bogs down your network. Which should you choose? Feature NVMe/TCP NVMe/RoCE v2 Complexity Low (Plug-and-Play) Moderate (Requires Tuning) Switch Req. Standard 100GbE Lossless (PFC/DCB) Latency Low Ultra-Low Host CPU Load Moderate Near-Zero The Bottom Line: If you have a specialized, high-performance workload and the budget for SmartNICs, go RoCE v2. If you want a cost-effective, high-density storage pool that "just works" with your existing gear, NVMe/TCP is the pragmatic choice. Learn More HighPoint CDI Hardware Storage Platforms RocketStor 4243AS 24-Bay CDI Hardware NVMe Storage Platform Blog: The Death of "Stranded Capacity" — Why Your NVMe Storage is Only 60% Efficient
- The Death of "Stranded Capacity" — Why Your NVMe Storage is Only 60% Efficient
In the modern data center, NVMe SSDs are the gold standard for performance. They are lightning-fast, dense, and increasingly affordable. However, there is a hidden crisis in traditional server architecture that is costing enterprises millions: Stranded Capacity. The Problem: The "Silo" Trap Traditionally, NVMe drives are installed directly into a server (Direct Attached Storage, or DAS). This creates a rigid 1-to-1 relationship between compute and storage. If Server A is a database node that is running out of space, but Server B is a web server with 15TB of empty NVMe sitting idle, Server A cannot "reach over" and use that extra capacity. That untapped 15TB is essentially Stranded. It is powered on, generating heat, and depreciating in value, but it is providing zero ROI. The Solution: Disaggregated "Liquid" Storage The RocketStor 4243AS solves this enabling IT specialists pull the NVMe drives out of the individual servers and placing them into a central, high-speed pool on the network fabric. This is the heart of Composable Disaggregated Infrastructure (CDI). By using NVMe-over-Fabrics (NVMe-oF), the RocketStor 4243AS transforms your storage into a fluid resource. · Provision on Demand: Need 2TB for a new AI training run? Simply channel it from the storage pool. · Scale Independently: If you need more storage, just add another RocketStor 4243AS. You no longer have to buy a whole new server just because you run short on disk space. · Maximize Utilization: Because any of the 120 supported host initiators can connect to the pool, your "Stranded Capacity" drops to near zero. Every gigabyte you pay for is put to work. The Hardware Advantage: The WDC RapidFlex™ C2000 Moving storage to the network usually comes with a "Latency Tax," but the RocketStor 4243AS uses the Western Digital RapidFlex™ C2000 fabric bridge to eliminate the bottleneck. By offloading the protocol stack to dedicated silicon, the remote storage performs as if it were plugged directly into the host’s local PCIe bus. Conclusion: Stop Buying Storage Silos In an era of rising energy costs and tightening IT budgets, "good enough" storage efficiency is no longer enough. Transitioning to a liquid storage model with the RocketStor 4243AS allows you to reclaim your stranded capacity, lower your TCO, and build an infrastructure that is as fast as the NVMe drives inside it. Learn More HighPoint CDI Hardware Storage Platforms RocketStor 4243AS 24-Bay CDI Hardware NVMe Storage Platform
- The Latency War
Achieving "Zero-Hop" Communication via Direct P2P Modern high-performance computing (HPC) workflows no longer measure performance in milliseconds. For industries such as High-Frequency Trading (HFT) and real-time AI inference, one’s competitive edge is now determined by the nanosecond. Despite industry reliance on cutting-edge PCIe Gen5 accelerators, the vast majority of standardized Gen5-enabled servers often suffer from "Micro-Latency"—tiny, cumulative delays that occur every time data has to travel through the system’s primary CPU. The following article attempts to shine a light on this phenomenon, and examine the most promising solution to this problem: enabling direct Peer-to-Peer communication between PCIe devices. The Enemy: The "CPU Hop" In a standard server architecture, data moving between two PCIe devices (e.g., from a high-speed NIC to a GPU) follows an inefficient path: 1. Device A sends data to the CPU Root Complex (this is tied to the host system mainboard) 2. The host CPU manages the interrupt and coordinates with System RAM. 3. The data is "bounced" back through the Root Complex to Device B. This "CPU Hop" doesn't just add physical distance; it introduces jitter. Because the CPU is busy managing the OS and background tasks, the time it takes to "bounce" that data can vary wildly. In a latency war, unpredictability is as damaging as a slow connection. The Solution: Direct P2P pathways via PCIe Switching Technology HighPoint’s Rocket 1600 Series PCIe Gen5 Switch Adapters eliminate "CPU Hop" by leveraging a Broadcom PEX89048 switch IC. These adapters are more than just expansion cards; they provide a high-speed routing fabric that enables Direct P2P (Peer-to-Peer) Communication between hosted PCIe devices, whether that be NVMe storage or Accelerator cards. Validated Architectural Benefits: The 115ns Advantage When we discuss "nanosecond" performance, we are referencing the verified hardware specifications of the Broadcom’s PCIe switching technology: Ultra-Low 115ns Port-to-Port Latency : the PEX89048 switch features a typical internal latency of just 115 nanoseconds (ns). Hardware-Level Routing: By utilizing the switch adapter’s integrated ARM Processing Unit, data is routed directly between devices across the x16 bus. Host CPU Bypass: Data moving from a NIC to a GPU—or an NVMe drive to a GPU—remains within the switch fabric. It never "bounces" to the host CPU, effectively slashing total transaction latency by up to 60% compared to traditional routing. Architecture in Action: Solving Critical Bottlenecks How does this nanosecond-level efficiency transform modern high-performance workloads? AI Inference Clusters : The Rocket 1600 adapter’s ability to provide direct pathways between accelerators enables Large Language Models (LLMs) to synchronize tensors across GPUs with near-zero delay, preventing the processing "stutter" common in standard architectures. Fintech & HFT Infrastructure : Market data arriving via a NIC can be moved directly to an FPGA or GPU for analysis in sub-microsecond timeframes, ensuring deterministic execution for time-critical trades. GPU-Direct Storage (GDS): Data hosted by the NVMe storage arrays can be fed directly into GPU memory. This bypasses the system RAM bottleneck, allowing for real-time processing of massive datasets at the full 32GT/s speed of the Gen5 bus. The Bottom Line: Deterministic Speed The "Latency War" isn't won by faster components alone; it’s won by the most efficient interconnect . By moving your I/O traffic to HighPoint’s modular PCIe switching architecture, you transition from a congested public highway to a private, deterministic expressway. Stop "bouncing" your data and start moving it at the speed of the bus. Learn More HighPoint PCIe Gen5 Switch Adapters Rocket 1628A PCIe Gen5 x8 4x MCIO Switch Adapter Previous Article: Inside the 48-Lane Fabric Next Up: The Edge Computing Puzzle
- The PCIe Bottleneck Crisis
Why the Physical Limitations of Standard Server Architecture Limits the potential of Gen5 Accelerators In the race for AI dominance and real-time data processing, we have arrived at a frustrating irony: we have the fastest CPUs and most powerful GPUs in history, but we are trying integrate them into systems with a design philosophy that hasn't fundamentally changed in decades. Modern IT architects are all too familiar with the resulting problem: Standard Motherboard Architecture is reaching its physical limitations. Even on the latest Gen5-enabled boards, the way we must physically arrange PCIe devices inside conventional server chassis prevents hardware from reaching its theoretical peak. The Proximity Trap: The Physics of 32GT/s PCIe Gen5 operates at a staggering 32GT/s per lane . At these frequencies, the physics of signal integrity become incredibly unforgiving. In a conventional server platform, your high-performance PCIe card must be plugged into a fixed slot soldered directly to the motherboard. Because Gen5 signals degrade rapidly over standard PCB traces (insertion loss), components must be installed as close to the CPU as possible. This creates the "Proximity Trap" : High Thermal Loads : High-power devices such as GPUs, 400G NICs, and NVMe arrays, when packed into cramped server chassis, can result in a massive thermal load. Thermal Throttling: A high thermal load within the chassis can result in PCIe devices overheating. When these components overheat, they downclock in order to protect sensitive hardware; a preventative measure known as thermal throttling. You might have paid for Gen5 speeds, but your hardware is running at Gen3 levels just to stay alive. Mechanical Crowding: Standard slot configurations limit your layout. If you need four GPUs but your motherboard only has two appropriately spaced slots, your expansion project grinds to a halt. The "Fixed Slot" Fallacy Modern enterprise workloads aren't "one size fits all." Yet, standard server platforms typically give you a fixed number of slots in fixed positions. This forces IT directors into a "Buy-a-Box" cycle: buying an entire new server just to get one more physical slot, even if they have plenty of unused CPU and RAM capacity in their existing rack. Breaking the Ceiling: The HighPoint MCIO Ecosystem To solve this, we have to stop thinking of PCIe as a "slot on a board" and start thinking of it as a Modular Switching Fabric . HighPoint’s MCIO PCIe Gen5 Expansion Adapters (like the Rocket 1628A ) decouple performance from physical proximity. 1. Intelligent Switching vs. Passive Passthrough Standard riser cards are nothing more than "dumb" PCIe connection solutions. HighPoint MCIO Switch Adapters, however, utilize a proven 48-Lane Gen5 Switching Architecture. The integration of a dedicated Switch IC and ARM processing unit ensures "traffic control" happens at the hardware level. The host CPU is no longer burdened with managing PCIe handshakes or lane allocation, allowing it to focus 100% on your application logic. 2. The Freedom of MCIO (Mini Cool Edge IO) By moving the signal into high-quality MCIO cabling, you can move the "endpoint" (the GPU or SSD) up to 1 meter away from the host slot with zero signal loss. This allows IT architects to: Relocate components: Move hot-running accelerators to high-airflow zones or the chassis perimeter. Horizontal Mounting: Use with HighPoint’s MCIO-PCIEX16-G5 Bridge to lay cards flat, fitting full-height performance into slim 1U or 2U enclosures. Scale Density: Transform one x16 slot into a hub for up to 8 direct NVMe drives or multiple GPUs. The Bottom Line: Performance Without Permission The bottleneck isn't the Gen5 spec—it's the standard way we build motherboards. By adopting an MCIO-based switching architecture, you are no longer asking your motherboard "permission" to add more power. You are building a composable, modular system that can scale as fast as the data demands. Is your current server layout choking your Gen5 hardware? Explore HighPoint’s PCIe Gen5 MCIO Switch Adapters – The New Standard for Modular I/O Rocket 1628A PCIe Gen5 x16 4x MCIO Switch Adapter Rocket 7638D PCIe Gen5 x16 2x MCIO & 1x CopprLink-CDFP Switch Adapter
- The Edge Computing Puzzle
Solving the 1U/2U Physical Constraint with Distributed I/O In Edge Data Centers, 1U and 2U rackmount servers remain the industry standard for maximizing compute density. However, these slim enclosures present a physical paradox: how do you fit the massive power of PCIe Gen5 into a chassis that is only 1.75 inches tall? Even with a Low-Profile Switch Adapter like the HighPoint Rocket 1628A , a vertical installation in a 1U chassis is physically impossible. To unlock Gen5 performance at the Edge, architects must move away from the "slot-on-motherboard" mindset and embrace a PCIe Distributed I/O Architecture. The Distributed Strategy: The Intelligent Hub & The Passive Bridge HighPoint’s Edge solution is a two-part ecosystem designed to solve the height restrictions of slim server chassis. The intelligence stays in the switch, while the physical flexibility is handled by the bridge. 1. The Hub: HighPoint’s Rocket 1628A Low-Profile Gen5 Switch Adapter The Rocket 1628A is designed function as the "brain" of the operation. Although it features a Low-Profile form factor, it houses a powerful Broadcom 48-lane switching fabric and four MCIO ports with x8 dedicated PCIe Gen5 lanes. The Role: It provides the Gen5 management, lane training, and 32GT/s signal integrity. The Challenge: Even horizontally, a Switch Adapter can be "crowded" by internal server components like power shrouds or fans. 2. The Solution: HighPoint’s MCIO-PCIEX16-G5 Bridge Card This is the accessory that makes 1U deployment viable. The MCIO-PCIEx16-G5 Bridge Card is a passive expansion component. It does not have a switch chip; instead, it can channel the Rocket 1628A’s PCIe Lanes and Intelligent resource management capabilities via high-integrity MCIO cabling. The "Remote Slot": Connecting the Bridge Card to the Rocket 1628A effectively "projects" a PCIe x16 slot to a different, more spacious part of the chassis. True 1U/2U Integration: Because the Bridge Card is small and passive, it can be tucked into the tightest horizontal riser spaces to host a GPU, NIC, or FPGA, while the Rocket 1628A manages the data traffic from a separate area within the server. Validated Architectural Benefits for the Edge By utilizing the Rocket 1628A as a centralized hub for one or more Passive Bridge Cards , Edge architects can bypass the physical limitations of standard 1U/2U server platforms: Engineering Challenge HighPoint Distributed Solution Result Height Restriction Low-Profile Switch + Passive Bridge Card. Full Gen5 x16 power in a slim 1U footprint. Signal Integrity Rocket 1628A manages 32GT/s signals. Lossless data over flexible 1m MCIO cables. Thermal Saturation Move hot devices away from the Switch & CPU. Cards stay 20% cooler in high-airflow intake zones. Architecture in Action: Composable Edge Nodes Imagine an Edge AI node that requires a 400G NIC and a high-performance GPU. · In a standard server chassis , these two hot-running cards are often forced into adjacent slots, leading to immediate thermal throttling and potential hardware failure. · With the HighPoint Ecosystem , the Rocket 1628A acts as the hub. Two MCIO cables run to two separate Bridge Cards mounted on opposite sides of the chassis. This is Composable Infrastructure. The Bridge Card provides the physical slot, but the Rocket 1628A provides the switching power. Together, they allow you to ignore the "fixed" layout of the motherboard and build for maximum efficiency. The Bottom Line: Intelligence Meets Flexibility HighPoint’s Rocket 1628A proves that a single Low-Profile form factor adapter card can drive a massive, distributed hardware ecosystem. By pairing the switch adapter’s intelligence with the Bridge Card’s physical flexibility, HighPoint enables IT architects to build Edge servers that rival the power of full-sized data centers. Is your Edge deployment limited by the physical constraints of your chassis? Learn More HighPoint PCIe Gen5 Switch Adapters Rocket 1628A PCIe 5.0 x16 4x MCIO Switch Adapter MCIO-PCIEX16-G5 Bridge Card
- The “Gen5 M.2 Slot deficit” in AI & HPC: Why Retimer-Based Expansion is the New Standard
As the industry transitions to PCIe Gen5, architects in AI, HPC, and high-performance storage are encountering a common physical bottleneck: onboard NVMe connectivity. With most enterprise platforms offering only one or two native Gen5 M.2 slots, scaling high-speed infrastructure has historically meant compromising on signal integrity or latency. Our Rocket 1604L, an Active Retimer-based Gen5 x16 M.2 Expansion Add-In-Card, was designed specifically to address this problem. The Signal Integrity Revolution: Motherboard-Grade Stability Unlike traditional passive bifurcation cards that suffer from signal attenuation at 32GT/s, the Rocket 1604L features an integrated Astera Labs Gen5 Retimer. This advanced silicon actively terminates incoming signals, eliminates electrical noise, and re-transmits a bit-perfect, "clean" signal to your devices. The result? The Rocket 1604L delivers the exact same performance and reliability as a native motherboard-integrated slot, ensuring 100% data integrity across all four M.2 ports. Why the Rocket 1604L is the Architecture of Choice: Near-Zero Latency: Operating at the Physical Layer (PHY), the 1604L provides a "transparent pipe" to the CPU. With processing delays measured in nanoseconds , it is the gold standard for latency-sensitive AI Inference and High-Frequency Trading (HFT) applications. Universal M.2 Versatility: Engineered for more than just storage, the 1604L’s transparent PCIe architecture supports the full spectrum of M.2 PCIe Accelerator Modules (TPUs/NPUs) and high-speed NICs alongside the latest Gen5 NVMe SSDs. Maximum Bandwidth: Leveraging native CPU bifurcation (x4/x4/x4/x4), the Rocket 1604L unlocks up to 64GB/s of aggregate throughput across four dedicated Gen5 channels. Mission-Critical Reliability: By resetting the PCIe "loss budget," our Retimer technology prevents the drive drop-outs and CRC errors common in passive expansion designs, providing the deterministic performance required for 24/7 high-uptime environments. Comparison of PCIe Expansion Architectures Architecture CPU Bifurcation Required? Signal Integrity Strategy Latency Primary Application Passive Yes None (Direct Copper) Lowest (Physical) Budget/Legacy Storage Active Retimer Yes Active Regeneration Near-Zero (PHY Layer) High-Density AI/HPC/M.2 Expansion Active Switch No Active Fabric Management Low (Switch Logic) Advanced Storage & Connectivity Expansion Solutions Expand Your Potential Without Compromise If your current project requires expanding Gen5 connectivity while maintaining a direct, low-latency path to the processor, the Rocket 1604L is the definitive solution. It doesn't just add ports; it extends your CPU’s native power. Learn More View Rocket 1604L Technical Specifications Have questions? Our team is here to help Blog: The Signal Integrity Revolution: Inside HighPoint’s Gen5 x16 Retimer Architecture Blog: 40% Smaller, 2x Longer Reach: Optimizing 1U Edge Servers for Gen5 AI Blog: Building the "Swiss Army Knife" of Edge AI: Modular Compute with M.2 AIPUs
- Rocket 8631x Series FAQ
Q1: Why does the RoketStor 8631D include 2x8-Pin power cables? A: Standard 8-pin cables are rated for 150W. The RocketStor 8631D uses a Native 12VHPWR connection to deliver a clean, direct 16-pin stream for maximum safety and performance. Q2: Can the RocketStor 8631D handle transient power spikes? A: Yes. The RocketStor 8631D was engineered to mitigate the risks of power spikes. The integrated 1300W industrial PSU, enables the enclosure to handle spikes up to approximately 1200W, ensuring the host system does not crash or reboot during peak GPU load. Q3: Can the RocketStor 8631C & 8631D support high-end industrial/datacenter grade GPUs such as the NVIDIA RTX PRO™ 6000 Blackwell Workstation Edition? A: Yes. The RocketStor 8631C/8631D is compatible with the NVIDIA RTX PRO™ 6000 Blackwell Workstation Edition, provided the GPU is already supported by the host system when installed directly into a standard PCIe slot. How it works: The RocketStor 8631C/8631D connects to the host system using a low-profile PCIe adapter (such as the rocket 7634D) that is natively supported by both Windows and Linux on Intel and AMD x86 platforms. Any modern system that supports PCIe Gen4 (or later) is generally compatible with this adapter and enclosure architecture. Learn More: Why HighPoint PCIe Switch Adapters Require No Device Driver Key compatibility principle: If a GPU: · Is recognized by the system BIOS · Is supported by the operating system and NVIDIA drivers · Functions correctly when installed directly in a PCIe slot Then it will also operate correctly when deployed inside the RocketStor 8631x, as the enclosure provides a transparent PCIe extension rather than a translation layer. What RocketStor 8631C/8631D does not change: · GPU driver requirements · OS-level GPU support · Application or CUDA compatibility The enclosure does not alter how the GPU is enumerated or managed by the system—it simply extends PCIe connectivity with full bandwidth and stability. In Summary: · Compatible with RTX PRO™ 6000 Blackwell · Works on Intel and AMD platforms · Supported on Windows and Linux · Requires PCIe Gen4 or newer host support